Heating up the Data Pipeline (Part 2)
In Part 1 we went through how to route events from Splunk to a 3rd party system without losing metadata. Now I'll show you how events can be transformed using Apache NiFi and be sent back to Splunk into the HTTP Event Collector.
Note: The following is not a step-by-step documentation. To learn how to use Apache NiFi you should read the Getting Started Guide.


As you can see, we are listening on Port 9996 and we allow 10 TCP connections at the same time.

The processor will use the Search Value property to find the ###LF### pattern ( or ###CR### ) and replace it with a literal \n (or \r).

We're extracting following attributes from our header:
event, host, index, meta, source, sourcetype, subsecond, time
Note that subsecond is a field within the meta key.
Data Provenance shows us that new attributes are available for this flowfile, after passing this processor:

The UpdateAttribute processor allows us to do string manipulations using the NiFi Expression Language. We are using a simple append function.
Note: For testing purposes I'm overwriting the index property to the value "test"
After this, the time attribute contains the epoch time including subseconds.

After the InvokeHTTP Processor has done its job, we can log into Splunk and search for our events. The events look as if they never left the Splunk Universe.
Note: The following is not a step-by-step documentation. To learn how to use Apache NiFi you should read the Getting Started Guide.
Simple Pass-Through Flow
As a first exercise we will create a simple flow, that only passes data through NiFi, without applying any complex transformations.
The following picture shows a high-level NiFi flow, that receives events in our custom uncooked event format with a TCP listener, then sends the data further into a transformation "black box" (aka Processor Group), which emits events in a format, that can be ingested into a Splunk HTTP Event Collector input.

Apache Nifi currently provides a rapidly growing number of processors (currently 266), which can be used for data ingestion, transformation and data output. Processors can be chained into flows and for manageability grouped into Processor Groups.
Let's take a closer look at what the ListenTCP processor does.
ListenTCP Processor
The ListenTCP processor is configured to listen on a predefined port for event data.
Each event is delimited by the \n linefeed character. If you remember, in part 1, we replaced all intra-event line feeds and carriage returns with a special character sequence.
Splunk's TCP output processor separates each event with the linefeed character "\n", the ListenTCP processor will based on the matching "Batching Message Delimiter"-propery, create a single (so-called) flowfile for each event sent by Splunk.
Each event is delimited by the \n linefeed character. If you remember, in part 1, we replaced all intra-event line feeds and carriage returns with a special character sequence.
Splunk's TCP output processor separates each event with the linefeed character "\n", the ListenTCP processor will based on the matching "Batching Message Delimiter"-propery, create a single (so-called) flowfile for each event sent by Splunk.
Right-clicking on a processor allows us to look or modify the configuration of a processor:

As you can see, we are listening on Port 9996 and we allow 10 TCP connections at the same time.
Using NiFi's Data Provenance feature, we can look at how the data looked, at every stage of the flow.
This is what the data looks like after the ListenTCP processor:
###time=1498849507|meta=datetime::"06-30-2017
21:05:07.214 +0200" log_level::INFO component::PerProcess data.pid::17656
data.ppid::564 data.t_count::68 data.mem_used::66.676 data.pct_memory::0.83
data.page_faults::767240 data.pct_cpu::0.00 data.normalized_pct_cpu::0.00
data.elapsed::84006.0001 data.process::splunkd data.args::service
data.process_type::splunkd_server _subsecond::.214 date_second::7 date_hour::21
date_minute::5 date_year::2017 date_month::june date_mday::30 date_wday::friday
date_zone::120|host=LT-PF0R53KD|sourcetype=splunk_resource_usage|index=_introspection|source=C:\Program
Files\Splunk\var\log\introspection\resource_usage.log###Start-of-Event###{"datetime":"06-30-2017
21:05:07.214
+0200","log_level":"INFO","component":"PerProcess","data":{"pid":"17656","ppid":"564","t_count":"68","mem_used":"66.676","pct_memory":"0.83","page_faults":"767240","pct_cpu":"0.00","normalized_pct_cpu":"0.00","elapsed":"84006.0001","process":"splunkd","args":"service","process_type":"splunkd_server"}}###End-of-Event###
Transformation into HEC Event Format (JSON)
While the HTTP Event Collector is capable of receiving raw data, we prefer to send the data in JSON format to retain all important metadata about the event.
Diving into the processor group reveals the full transformation flow:

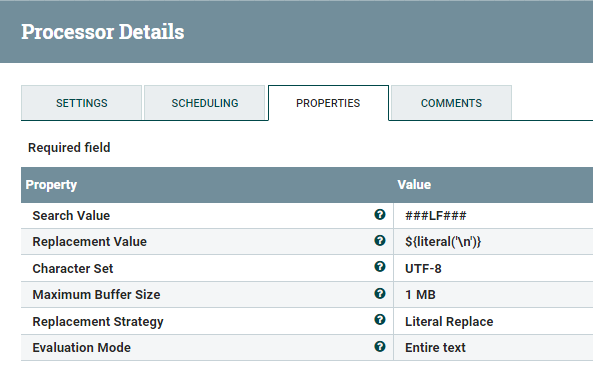
ReplaceText Processor
The first step in our transformation is to replace our custom line breaker and carriage return with their real character. For this, we will use the ReplaceText Processor twice.
The processor will use the Search Value property to find the ###LF### pattern ( or ###CR### ) and replace it with a literal \n (or \r).
ExtractText Processor
The next step is to extract all metadata from the raw event. In Apache NiFi, for each flowfile there is a standard set of attributes available. Using the the ExtractText processor, we can run regular expressions over the flowfile content and add new attributes.
We're extracting following attributes from our header:
event, host, index, meta, source, sourcetype, subsecond, time
Note that subsecond is a field within the meta key.
Data Provenance shows us that new attributes are available for this flowfile, after passing this processor:

UpdateAttribute Processor
Splunk's _time -field contains an epoch timestamp, but without subseconds. From our event's meta key, we have have extacted an attribute subsecond using the ExtractAttribute processor.The UpdateAttribute processor allows us to do string manipulations using the NiFi Expression Language. We are using a simple append function.

Note: For testing purposes I'm overwriting the index property to the value "test"
After this, the time attribute contains the epoch time including subseconds.
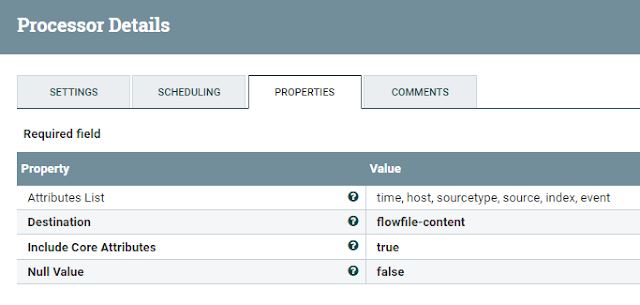
AttributesToJSON Processor
Now that we have extracted and transformed all the necessary data, we want to put the data into a JSON document format that Splunk's HTTP Event Collector accepts.
Using the AttributesToJson Processor, we just add the attributes we want to use as top elements to the "Attributes List"-property and set the "Destination"-property to "flowfile-content":
The flowfile will then look like this (example):
{
"host": "myhost",
"index": "test",
"sourcetype": "splunkd",
"time": "1499608510.417",
"source": "C:\\Program Files\\Splunk\\var\\log\\splunk\\metrics.log",
"event": "07-09-2017 15:55:10.417 +0200 INFO Metrics - group=thruput, name=index_thruput, instantaneous_kbps=0, instantaneous_eps=0, average_kbps=0, total_k_processed=0, kb=0, ev=0"
}
InvokeHTTP Processor
Last but not least, we want to send the flowfile to the Splunk HTTP Event Collector. For this we will use the InvokeHTTP Processor. The processesor issues a POST request to HEC and sends the JSON document as payload.
To send to HEC the processor needs to be properly authentication. To achieve this, we add a property "Authorization" with the value "Splunk" followed by the HEC Input Token.

Note: When using the HTTPS endpoint for HEC, you have to create a NiFI SSL Context Controller Service. This service points to a Java Keystore/Truststore, that contains the Splunk Root Certificates. Otherwise, the connection will not be trusted and rejected by NiFi.
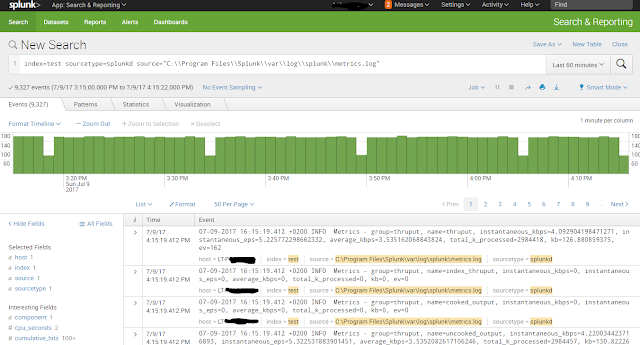
After the InvokeHTTP Processor has done its job, we can log into Splunk and search for our events. The events look as if they never left the Splunk Universe.

Conclusion
While the presented NiFi Flow does not change the data, it shows how easy it is to change data formats on-the-fly. This flow can be easily adjusted to your requirements.
Part 3 will be all about use cases. I will show how Apache NiFi can enrich data and do content based routing.
Stay tuned!


Comments